היי! כאן אמיתי בונה עם הניוזלטר השבועי על AI ופרודוקטיביות.
המהדורה של השבוע תעסוק ב-GPT-Image 2, מודל התמונות החדש של OpenAI.
בגלל שכולנו כבר עייפים מהכרזות דרמטיות על מודלים וכלים חדשים, הפעם אהיה יחסית ממוקד: מה השתנה ביחס למה שהכרנו, איך אפשר לעבוד איתו טוב, רעיונות לשימוש ופרומפטים שתוכלו לנסות בעצמכם.
תקציר הפרקים הקודמים
עד לפני שנה מודלי תמונה ומודלי שפה היו שני עולמות נפרדים.
היו לנו את Midjourney, Ideogram ו-Flux שפיתחו מודלי דיפוזיה והובילו בתחום התמונות, ובתחום השפה היו לנו את החברות הגדולות OpenAI, גוגל ואנתרופיק.
לפני שנה בערך OpenAI הוציאה את מודל התמונות המולטימודלי הראשון שלה - כלומר אותו מודל שמייצר טקסט התחיל לייצר תמונות.
זו הייתה קפיצת מדרגה משמעותית, כי המודל פתאום מבין מה רוצים ממנו בצורה הרבה יותר עמוקה, ויודע לעשות הסקה, תכנון וניתוח לפני שהוא יוצר את התמונה.
אבל הכתר לא נשאר אצלם הרבה זמן.
מיד אחר כך גוגל הוציאה את nano banana, מודל התמונות המולטימודלי שלה ואחר כך את השדרוג שלו שהחזיקו את ההובלה עד עכשיו.
ומה השתנה עכשיו?
בשבוע שעבר OpenAI הוציאה את GPT-Image 2, הגרסה החדשה של מודל התמונות שלה, ביחד עם GPT 5.5 ולקחה בחזרה את הכתר - אפשר אפילו להגיד שבפער גדול.
את הפער מרגישים בבירור בתוצאות שמקבלים ממנו וזה החלק הכי חשוב, אבל אפשר לראות אותו גם בבנצ׳מארקים באופן ברור לחלוטין:
אז מה חדש במודל הזה לעומת הקודמים?
יכולת ירידה לפרטים: המודל מצליח להוציא אינפוגרפיקות פשוט מדהימות, יותר ממה שהכרנו דרך NotebookLM וננו בננה (דוגמאות בהמשך).
יצירת טקסט מושלם בתמונה: באנגלית מושלם ובעברית ממש כמעט מושלם. אם יש ממש הרבה טקסט הוא לפעמים מפשל בעברית, אבל זה כבר מספיק טוב בשביל רוב השימושים.
יצירת סדרת תמונות תואמות: המודל יודע ליצור סט של תמונות עם אותו סגנון עיצובי או דמויות (מעולה לקמפיינים).
שליטה ב-Aspect ratio: ניתן להמיר לאיזה גודל שרוצים בקלות, למשל 1:1, 4:3, 16:9 וכו׳. פשוט מבקשים ממנו ומקבלים
יכולת עריכה: אחרי שיצרתם תמונה אפשר לצבוע אזורים ספיציפים ולערוך רק אותם
הכי חשוב: הוא פשוט מבין מה רוצים ממנו ומייצר תוצאות מדהימות ומפתיעות - אפילו מפרומפטים פשוטים.
להמחשה, הנה כמה דוגמאות מהניסיונות שלי בשבוע האחרון עם פרומפטים שתוכלו לנסות מחר בבוקר:
״האנטומיה של ברקוני״
הפרומפט: ״תחקור על “ברקוני” ותייצר אינפוגרפיקה מרשימה בסגנון נשיונל גיאוגרפיק שמראה את האנטומיה של היצור הזה על סמך מה שמצאת״ (וגם צירפתי תמונה שלו מהאינטרנט)
״אינפוגרפיקה על העבודה שלי״ (שימוש ביכולת הזכרון המובנה של הצ׳אט)
הפרומפט: ״על סמך מה שאתה יודע עלי תייצר אינפוגרפיקה של העבודה שלי בסגנון ייחודי (צירפתי גם תמונה שלי)
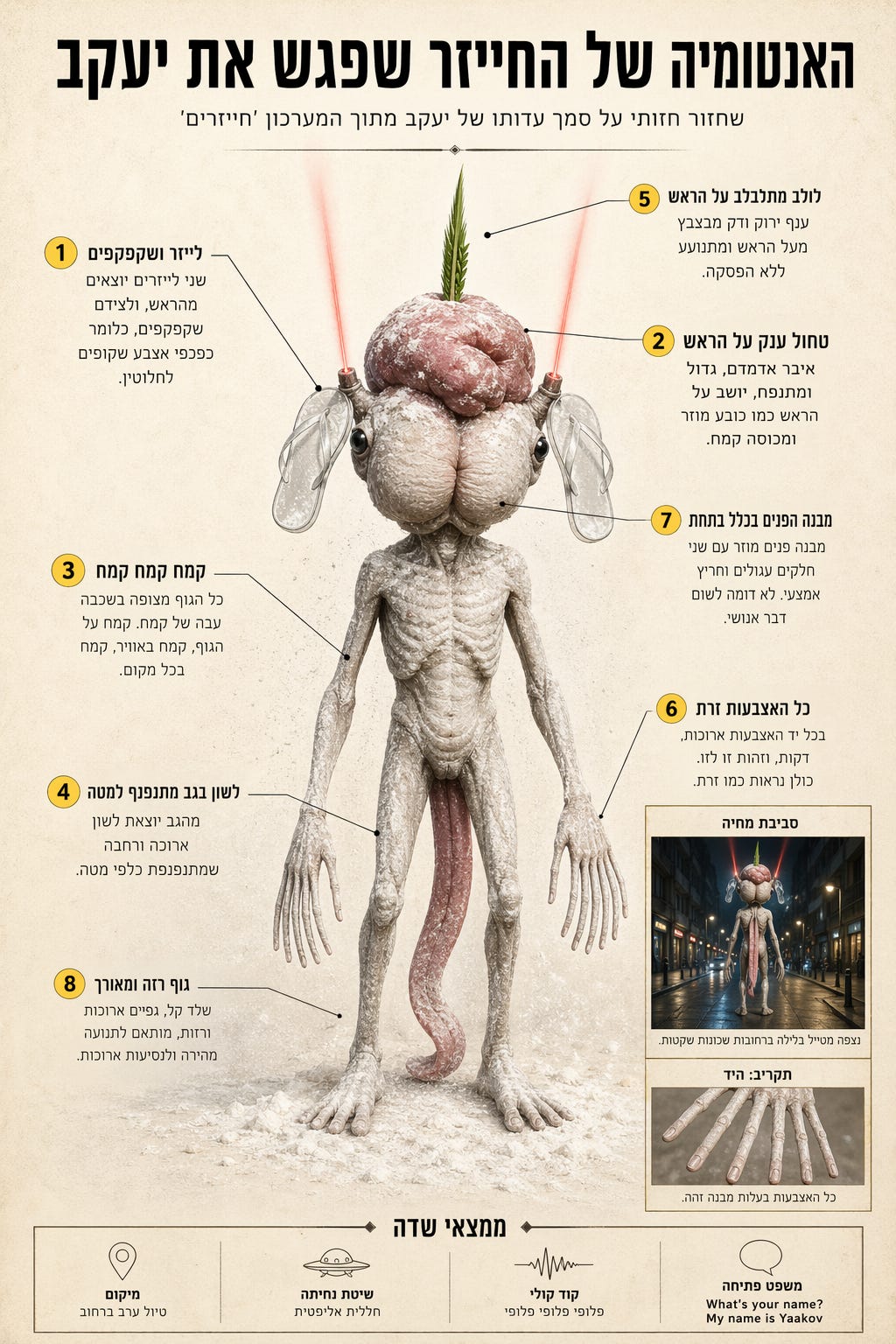
״החייזר שפגש את יעקב״
הפרומפט: תייצר לי אינפוגרפיקה אנטומית של החייזר שיעקב פגש מתוך המערכון ״חייזרים״ של אסי וגורי על סמך תמלול של המערכון (הוספתי את התמלול של הסרטון היוטיוב וגם היו פה עוד כמה ניסיונות ומשחקים עם הפרומפט עד שהגעתי לתוצאה הזו.
״קריאה בכף יד״
הפרומפט ממש ארוך שמבוסס על דוגמה שמצאתי בטוויטר, שדרגתי והתאמתי לעברית. תוכלו למצוא אותו בקישור הזה ויצרתי גם GPT שתוכלו לשלוח לו תמונה של היד שלכם ולקבל קריאה בעברית.
״מ.ק 22: הסרט״
הפרומפט: תחקור על הסדרה מ.ק 22 ותכין פוסטר לסרט “מ.ק 22: הסרט” עם דמויות אנושיות שנראות כמו הדמויות המצויירת (צירפתי כמה תמונות רפרנס מהאינטרנט)
איך משתמשים?
הדרך הכי פשוטה היא בתוך ChatGPT באתר או באפליקציה - צריך מנוי בתשלום. פשוט מבקשים שיצור תמונה או בוחרים בטאב “Image”. שימו לב שאתם על מצב חשיבה שמוציא תוצאות טובות יותר.
דרך נוספת להשתמש בו היא דרך אפליקציית Codex שגם היא כלולה במנוי של ChatGPT ובאופן כללי תופסת תאוצה בשבועות האחרונים. צריך להתקין את ה-Skill שנקרא Image gen ואז פשוט מבקשים את התמונה שרוצים.
לפי מה שקראתי - נכון לעכשיו אפשר להשתמש בו דרך Codex בצורה מוגבלת גם ללא מנוי בתשלום, אבל לא יצא לי לבדוק את זה בעצמי.
היתרונות המרכזיים בעבודה דרך Codex הם שהתמונות נשמרות בתיקיה לוקאלית במחשב וגם שאפשר לשלב את את זה עם Skills נוספים או אוטומציות.
בנוסף, יש אפשרויות נוספת כמו לגשת למודל דרך ה-API ודרך אתרי צד שלישי כגון Fal.ai, Freepik שיכולות להיות רלוונטיות אם יש לכם מנוי לכלים האלה.
השינוי האמיתי: צוואר הבקבוק עובר אלינו
כל מודל חדש הוא קפיצה, אבל בתחושה שלי לפחות - המודל הזה עבר רף קריטי מסוים.
זה מרגיש שהוא כל כך טוב שהוא יכול לייצר עבורנו כמעט כל תוצר ויזואלי שנרצה,
ושם המשחק הוא כבר לא לכתוב את הפרומפט המושלם או להכיר את כל הטריקים שישפרו את התוצאה,
אלא להצליח לחשוב על רעיונות יצירתיים, לדמיין אותם - ואז להצליח לתאר אותם במילים או להביא את הרפרנסים המתאימים.
זה אמנם נשמע פשוט - אבל האמת היא שזה משהו שרובנו לא מתורגלים בו.
למי שיש רקע בעיצוב או צילום יש יתרון מסויים, כי הם רגילים לחשוב במונחים ויזואלים יותר - אבל לרובנו, זה שריר חדש שצריך להתחיל לבנות.
אז לומדים לדמיין יותר טוב?
הנה כמה שיטות שאני משתמש בהן ביום-יום:
1. הנדסה לאחור
קחו תוצר ויזואלי שאהבתם, לא משנה אם הוא נוצר ב-AI או לא. פוסטר שראיתם, צילום, פרסומת או אינפוגרפיקה.
תעלו אותו למודל ותבקשו ממנו: “תן לי פרומפט שייצר תוצר כזה”. הוא ינתח עבורכם את הסטייל, התאורה, הקומפוזיציה והסגנון, ויחזיר לכם פרומפט עבודה שאפשר לערוך ולהשתמש בו.
2. תנו למודל לכתוב את הפרומפט עבורכם
במקום לשבור את הראש ולנסות לתאר את התמונה בעצמכם, פתחו צ׳אט נפרד ובקשו: “אני רוצה תמונה ל-X. תכתוב לי בריף ויזואלי מפורט - נושא, סצנה, תאורה, קומפוזיציה, פלטת צבעים, וסגנון”. קחו את הפלט שלו ושלחו אותו למחולל התמונות. המודלים יותר טובים מאיתנו בלתאר תמונות, פשוט כי הם קראו מיליארדי תיאורים ויזואליים.
3. תבקשו מהמודל להפתיע אתכם
במקום לנסות להגדיר במדוייק מה רוצים, תארו לו את רק את המטרה שלכם. למשל: “אני רוצה לייצר תמונה לפוסט לינקדאין המצורף שתיהיה מצחיקה ומעניינת, תן לי 4-5 רעיונות שונים ומפתיעים להשראה״
זה הופך את המודל ממבצע משימה לשותף יצירתי, והרבה פעמים הוא יחשוב על דברים שלא היו עולים לכם בראש בכלל.
4. קחו השראה מאחרים
יש באינטרנט המון דוגמאות לשימוש במודל הזה ומודלי תמונות בכללי. הנה כמה מקומות שתוכלו לראות מה אחרים עושים איתם ולקבל השראה: