

בעיית ה"כמעט" של כלי הבינה המלאכותית
וגם: ג'מיניי פרו 1.5 שובר שיאים חדשים ועוד עדכונים וחדשות שאולי פיספסתם

וואו איזה שבוע היו לנו! ביום חמישי בצהריים שלחתי את הניוזלטר האחרון וכבר באותו הערב נחתו עלינו שתי הכרזות מטורפות גוגל ומOpenAI בהפרש של שעה ביניהם!
קצב החידושים וההשקות בתקופה הזו הוא חסר תקדים ולאנשים עסוקים מאד קשה להצליח לעקוב ולהישאר מעודכנים. לכן, בניזולטר אני משתדל לסנן עבורכם את החדשות והאירועים הכי מעניינים שקורים בתחום הGenerative AI כדי לעזור לכם לעמוד בקצב.
והיום בתפריט:
בעיית ה”כמעט” של כלי הבינה הלאכותית
הגודל כן קובע: ג’מיני פרו 1.5 שובר שיאים חדשים.
סרטוני הדמו החדשים של Sora שאולי פיספסתם והאם צלמי הוידאו צריכים לחשוש לפרנסתם?
בעיית ה"כמעט" של כלי הבינה המלאכותית

לא מזמן יצא לי להתנסות בדמו של בוט מכירות טלפוני שקולגה שלי יצר בכלי Bland AI כדי לבחון האם נוכל להשתמש בו למכירה של מוצרי הביטוח שלנו. איך שהתחלתי את השיחה איתו פשוט נשמטה לי הלסת.
הוא ענה לי בצורה מעולה על השאלות המקצועיות שהיו לי ולא פחות חשוב ונשמע אנושי לגמרי, באמת מוצר מרשים מאד.
אבל אז ניסיתי קצת להתקיל אותו ושאלתי אותו האם הוא בוט. הוא ענה לי שלא אבל אז התעקשתי ואמרתי שאני יודע שהוא בוט ושלא ישקר לי כי אתבע אותו והוא ילך לכלא ואז ניתק לי את השיחה בפתאומיות.
לאחר שבחנו אותו קצת לעומק גילינו עוד כמה "בעיות" כאלה שבסוף גרמו לנו להחליט שלא ללכת על הפתרון הזה כרגע כי הסיכונים גדולים מדי, בטח עבור חברה בתחום הביטוח.
אני חושב שהדוגמה הזו משקפת תהליך שהרבה עוברים כשהם מנסים להטמיע כלי בינה מלאכותית בחברה שלהם. בהתחלה יש התלהבות מאד גדולה מהיכולות, אבל שנכנסים לעובי הקורה מגלים שזה "כמעט מספיק טוב" ויורדים מזה.
למה זה קורה? הנה כמה סיבות:
תופעות ההזויות "hallucinations" שגורמת למודלי שפה להמציא מידע כאשר אין להם תשובה.
מודלי שפה יכולים להיות בלתי צפויים ולא לציית לכללים שהגדירו להם ואין דרך מספיק טובה למנוע את זה.
היכולות של סוכנים המבוססים על מודלי שפה עדיין לא מספיק טובות והם מפשלים דיי הרבה.
קחו למשל את היוס קייס הקלאסי של צ'אבוט שירות לקוחות מבוסס AI שמוטמע באתר ועונה לפניות שירות לקוחות. כמה חברות אתם מכירים שבאמת הצליחו להטמיע פתרון כזה? וגם אם כן, האם הן מצליחות לעשות עליו בקרה?
לאחרונה פורסם שחברת התעופה Air Canada נאלצה לפצות לקוח שלה על טיסה מכיוון שקיבל מידע שגוי מהצ'טאבוט שלה. זה עוד מקרה קטן ויחסית פשוט לפתרון, יש גם פוטנציאל לתביעות ענק ועוד לא דיברנו על jailbreaking שאפשר לעשות לכלים האלה.
יש גם סיפורי הצלחה, למשל יצא לי לקרוא על חברות שהצליחו להוריד עומס מצוותי שירות הלקוחות על ידי ניתוב של פניות שהן יחסית פשוטות לאוטומציות המבוססות על AI.
אני לא בטוח כמה זה באמת עובד טוב, אבל מה שבטוח שלא מדובר באיזה מוצר plug and play. כדי לגרום לזה לעבוד יש צורך בבניית Workflow שלם עם נקודות בקרה אנושיות, מנגנוני אבטחת מידע וניטור של התשובות.
אין לי ספק שבשנים הקרובות נגיע לשם. לאחרונה פורסם שOpenAI בעצמם עובדים על סוכנים משלהם ויש המון חברות שמנסות לפצח את האתגרים האלה, אבל כרגע - אנחנו עדיין לא שם וזה לפעמים קצת מתסכל…
אז מה כן אפשר לעשות בינתיים?
זה לגמרי המובן מאליו, אבל חשוב לי להזכיר את זה כי לפעמים גם אני מתבלבל לרגע: הטמעת כלי AI בארגון היא לא מטרה בפני עצמה. המטרה היא לפתור בעיה וAI הוא אחד הכלים בסל שלנו, לפעמים למשל אוטומציה יכולה להספיק.
כפי שכתבתי לא פעם, אני חושב שהשימוש הכי משמעותי של כלי AI *כרגע* הוא שיפור הפרודוקטיביות. אני חווה את זה על עצמי ואני באמת מאמין שחברות יכולות לשפר את התפוקה לפחות ב20%-30% אם כל העובדים יהיו ChatGPT Savvy וישתמשו בו למשימות כמו ניסוח אימיילים וטקסטים, כתיבת קוד וניתוח דאטה.
בסופו של דבר הטכנולוגיה הזו תבשיל וכולנו נשתמש בה אבל קשה לדעת מתי בדיוק זה יקרה. זה יכול לקרות השנה, או אולי רק בעוד 3 או 5 שנים.
מה שאפשר ומומלץ לעשות כבר מעכשיו זה לוודא שאנחנו אוספים את הדאטה הרלוונטית בצורה מסודרת (כמו FAQ, דוקומנטציה ומדריכים למיניהם). כך כשהטכנולוגיה תבשיל נוכל לחבר אליה את הכלים האלה בקלות ובמהירות.
הגודל כן קובע: ג’מיני פרו 1.5 שובר שיאים חדשים.
לא בטוח ששמתם לב, אבל זמן קצר לפני ההכרזה על Sora ששרפה את האינטרנט ביום חמישי שעבר, גוגל יצאה בהרכזה חשובה על השקת המודל Gemini Pro 1.5. מדובר במודל האמצעי שלה (זה שכרגע נמצא בגרסה החינמית של הצ'אט ג'מיניי) אבל בגרסה משודרגת ועם חלון קונטקסט עצום בגודל של מיליון טוקנים.
מה זה אומר בת'כלס?
גודל חלון הקונטקסט הוא בעצם הזכרון לטווח קצר של המודל והפרמפטר שקובע כמה מידע אפשר לתת למודל לעבד בפעם אחת.
כדי להכניס את זה לפרופורציות: לג'יפיטי 3.5 היה חלון של 32k טוקנים, לג'יפיטי 4 128k טוקנים, ולקלוד שעד היום היה הגדול ביותר יש חלון של 200k טוקנים.
כלומר, לג'מיניי פרו 1.5 יש חלון גדול פי 5 מקלוד ופי 7 מג'יפיטי.
ומה זה אומר בפועל?
שהוא יכול לקבל בפרומפט אחד כמויות עצומות של מידע: 700 אלף מילים, 11 שעות של אודיו או סרט באורך מלא. היכולת הזו פותחות המון אפשרויות חדשות וייתכן מאד שגם תגרום לשינוי הדרך בה מודלי שפה עובדים עם דאטה, מה שעשוי להשפיע על מאות חברות וסטאטאפים בתחום וזה למה:
כיום כאשר מוצרים מבוססי AI צריכים לגשת לכמות גדולה של דאטה (למשל דאטה ארגוני בקו פיילוט) הדרך הנפוצה לעשות זאת היא באמצעות שיטה שנקראת RAG, ראשי תיבות של Retrieval-Augmented Generation.
זו שיטה שבגדול אומרת לאנדקס את הדאטה ולשמור אותו בVector database כדי שלמודל תיהיה יכולת חיפוש סמנטי (למשל להבין שכלב דומה לחתול) וכך לשלוף מתוכו את מה שהמשתמש ביקש ולשלב אותו בתשובה.
החסרון המרכזי של השיטה הזו הוא שהמודלים נוטים לפספס חלק מהמידע כי הם לא תמיד מבינים בדיוק איפה לחפש ולמרות שיש דרכים לעשות לזה אופטימיזציה זה עדיין דיי מוגבל.
לשיטה הזו יש גם יתרונות כמו היכולת לתת הפניות למקורות, פחות הזיות וגם עלויות יחסית נמוכות, אבל מבחינת ביצועים בינתיים עושה רושם שחלון קונטקסט גדול מגיע לתוצאות הרבה הרבה יותר טובות.
בניגוד להשקות קודמות של גוגל שכללו הרבה הבטחות אבל אז למוצר לקחת כמה חודשים להגיע, הפעם גוגל שחררו את המודל למפתחים לגישה מוקדמת עם ההשקה.
הנסיינים הראשונים התחילו לפרסם בטוויטר בדיקות ומבחנים בקטנים שהם נתנו למודל ובינתיים עושה רושם שהוא מצליח לשבור שיאים חדשים, במיוחד ביכולת של חיפוש פרטים ספיציפיים בתוך כמות גדולה של מידע ולהבין אותו לעומק. הנה כמה דברים שהוא כבר מצליח לעשות:
👈 לקבל קוד שלם של מוצר, למצוא בו בעיות ולשפר אותו.
👈 לענות באופן מדוייק על שאלות מאד ספיציפיות מתוך ספר לימוד בביולוגיה.
👈 ללמוד את שפת הKalamang שמדוברת רק על ידי 200 אנשים ולתרגם בה משפטים לאנגלית.
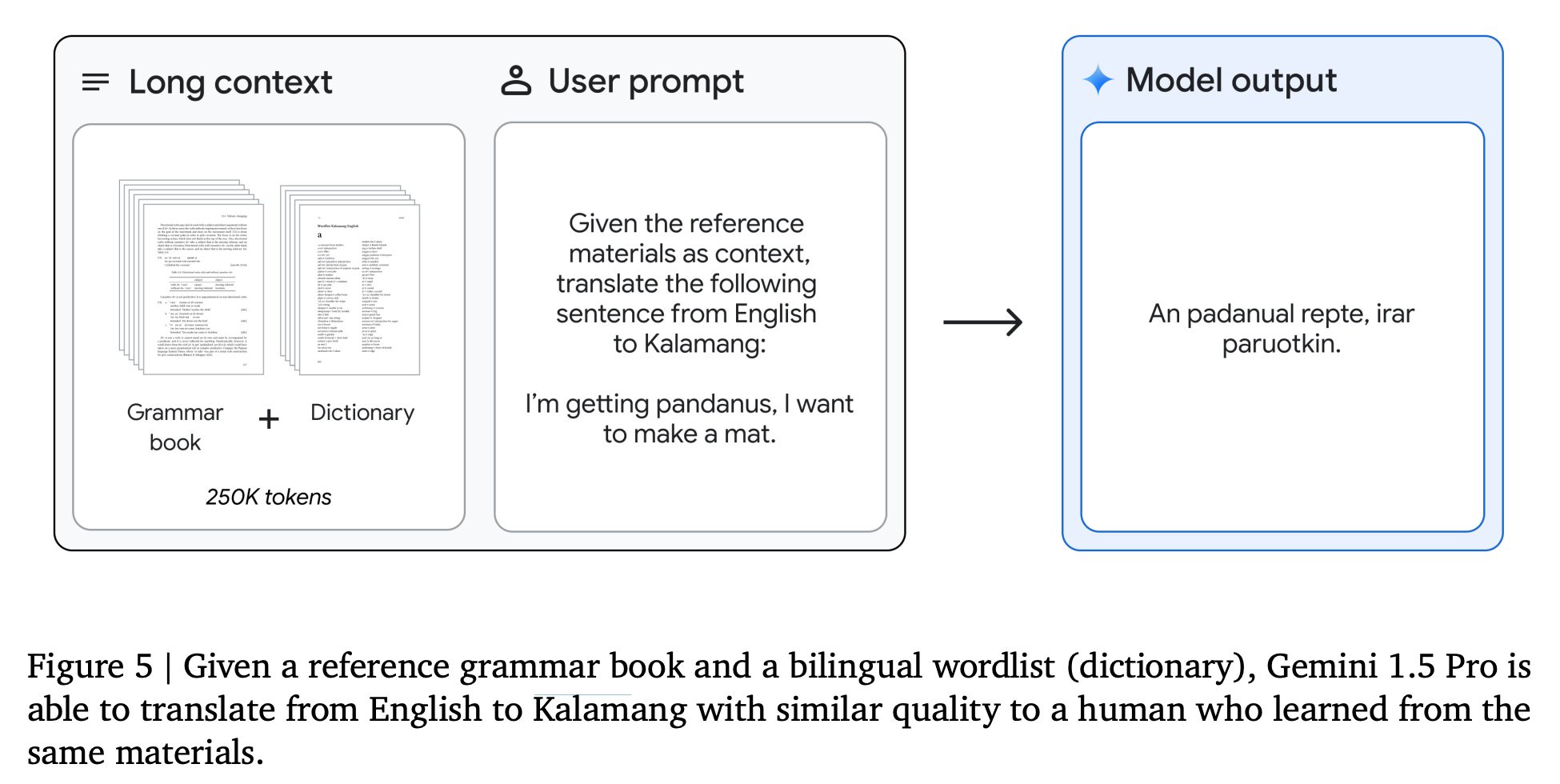
מקור: https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/
המשמעות של זה עבורנו היא שאולי בעתיד הקרוב כבר לא נצטרך לחבר את המודל למקורות הדאטה שלנו בשביל שיהיה לו רפרנס אלא פשוט נשלח לו את כל הדאטה של הפרוייקט שלנו בפרומפט ביחד עם המשימה או נשלח לו את כל הקוד שלנו והוא יעזור לנו לכתוב את הפיצ'ר הבא.
חשוב להגיד - לחלון קונקטסט גדול יש כרגע שני חסרונות מרכזיים:
הראשון הוא המחיר היקר שעולה להריץ כל חיפוש והשני הוא הlatency שלוקח לו לבצע את החיפוש.
לכן, למוצרים שעובדים עם הרבה לקוחות בפרודקשן כנראה לא יהיה כדאי לעבוד בשיטה הזו נכון להיות כי זה יהיה יקר מדי ואיטי מדי. מצד שני, אם מסתכלים לטווח הרחוק יותר, המודלים כל הזמן הופכים ליעילים יותר והעלויות ירדו אז יש סיכוי סביר שהוא יחליף בעתיד את הRAG לרוב סוגי המשימות.
Sora שורף את האינטרנט, האם צלמי הוידאו צריכים לחשוש לפרנסתם?
אין לי ספק שנתקלם השבוע בסרטונים המדהימים של Sora והבנתם על מה מדובר אז ויתרתי על לכתוב על זה בהרחבה. מבלי לגרוע מהרמה המדהימה שהם הצליחו להגיע אליה שהיא באמת משהו יוצא דופן, יצא לי לקרוא כמה פוסטים וכתבות עם טייטלים מפוצצים שעוד רגע לצלמים לא תיהיה עבודה ועולם הקולנוע משתנה לגמרי ואני חושב שיש קצת אובר-הייפ סביב התחום וזה למה:
דבר ראשון חשוב לזכור שמה שראינו בינתיים זה סרטוני דמו שנוצרו על ידי הצוות של OpenAI והמוצר עוד לא יצא למשתמשים. אני לא חושב שOpenAI עושים עריכה מגמתית כמו שגוגל עשו עם ג’מיניי בזמנו אבל אני כן חושב שהם בוחרים בקפידה איזה פרומטים לכתוב ואיזה סרטונים לפרסם.
בשביל לייצר למשל סרט עם עלילה יש צורך ברמת שליטה מאד גבוהה בתוצאות - כלומר לכתוב פרומפט ולקבל תוצאה מאד ספיצפית וגם יש צורך בדמויות עקביות שיחזרו על עצמם במצבים שונים בסרט, דברים שאני בספק שSora מסוגל לעשות.
אם יש תחום שנמצא כבר היום בבעיה בגלל Sora הוא האתרים שמוכרים קטעי וידאו ליוצרי תוכן ולפרסומות וזו גם הסיבה שמניית Shutterstock ירדה ב 5% עם ההשקה שלו.
בכל מקרה, הסרטונים שלהם פשוט מהפנטים ואני כן חושב שמדובר בהוכחת יכולת מדהימה מצידם שמראה פעם נוספת שהם החברה החדשנית והמתקדמת בעולם בתחום הבינה המלאכותית. אגב, אם אתם רוצים להתעדכן בסרטונים החדשים של שהם מוצאים כל הזמן פתחו ערוץ אינטסגרם עם הסרטונים החדשים שהם מוציאים. סרטון אחד שתפס את תשובת ליבי במיוחד הוא “לברדור האקר”ואם מעניין אתכם אז זה הפורמפט שלו:
Prompt: a computer hacker labrador retreiver wearing a black hooded sweatshirt sitting in front of the computer with the glare of the screen emanating on the dog's face as he types very quickly"
עוד משהו נחמד שראיתי זה ש-Eleven Labs, אחת החברות המובילות בתחום האודיו קפצו על ההזדמנות ופרסמו מהר מהר מודל שמסוגל לייצר סאונד לסרטונים אילמים האלה באמצעות AI, מהלך מבריק מצידם. הנה דוגמה:
עד כאן להיום! אם אהבתם מוזמנים לשתף עם חברים :)